Serving Overview
What is FlexFlow Serve
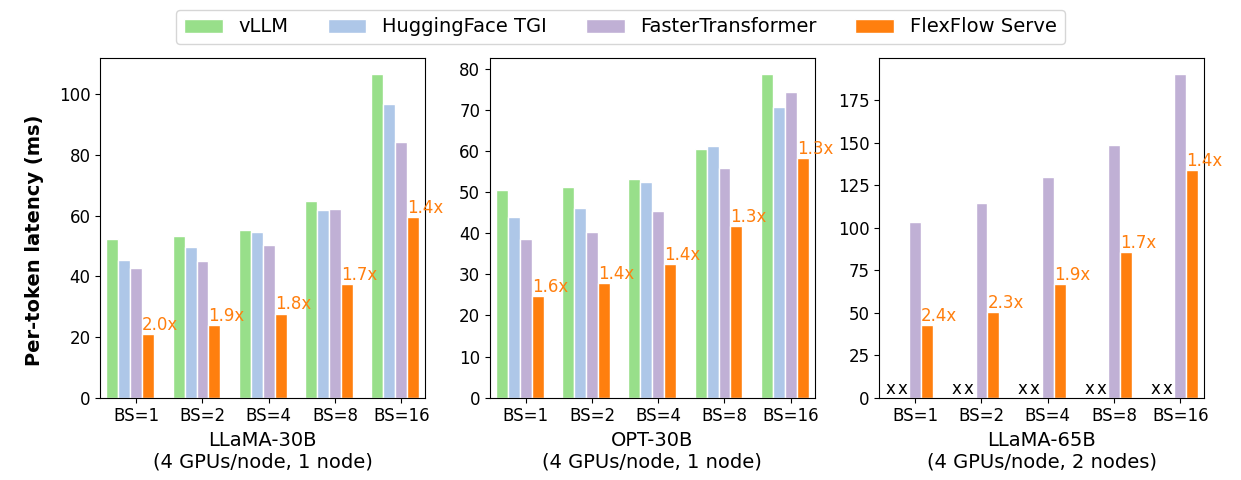
The high computational and memory requirements of generative large language models (LLMs) make it challenging to serve them quickly and cheaply. FlexFlow Serve is an open-source compiler and distributed system for low latency, high performance LLM serving. FlexFlow Serve outperforms existing systems by 1.3-2.0x for single-node, multi-GPU inference and by 1.4-2.4x for multi-node, multi-GPU inference.
Quickstart
The following example shows how to deploy an LLM using FlexFlow Serve and accelerate its serving using speculative inference. First, we import flexflow.serve and initialize the FlexFlow Serve runtime. Note that memory_per_gpu and zero_copy_memory_per_node specify the size of device memory on each GPU (in MB) and zero-copy memory on each node (in MB), respectively.
We need to make sure the aggregated GPU memory and zero-copy memory are both sufficient to store LLM parameters in non-offloading serving. FlexFlow Serve combines tensor and pipeline model parallelism for LLM serving.
import flexflow.serve as ff
ff.init(
num_gpus=4,
memory_per_gpu=14000,
zero_copy_memory_per_node=30000,
tensor_parallelism_degree=4,
pipeline_parallelism_degree=1
)
Second, we specify the LLM to serve and the SSM(s) used to accelerate LLM serving. The list of supported LLMs and SSMs is available at supported models.
# Specify the LLM
llm = ff.LLM("meta-llama/Llama-2-7b-hf")
# Specify a list of SSMs (just one in this case)
ssms=[]
ssm = ff.SSM("JackFram/llama-68m")
ssms.append(ssm)
Next, we declare the generation configuration and compile both the LLM and SSMs. Note that all SSMs should run in the beam search mode, and the LLM should run in the tree verification mode to verify the speculated tokens from SSMs.
# Create the sampling configs
generation_config = ff.GenerationConfig(
do_sample=False, temperature=0.9, topp=0.8, topk=1
)
# Compile the SSMs for inference and load the weights into memory
for ssm in ssms:
ssm.compile(generation_config)
# Compile the LLM for inference and load the weights into memory
llm.compile(generation_config, ssms=ssms)
Finally, we call llm.generate to generate the output, which is organized as a list of GenerationResult, which include the output tokens and text.
result = llm.generate("Here are some travel tips for Tokyo:\n")
Incremental decoding
Expand here
import flexflow.serve as ff
# Initialize the FlexFlow runtime. ff.init() takes a dictionary (as a positional argument) or named key-value parameters
ff.init(
num_gpus=4,
memory_per_gpu=14000,
zero_copy_memory_per_node=30000,
tensor_parallelism_degree=4,
pipeline_parallelism_degree=1
)
# Create the FlexFlow LLM
llm = ff.LLM("meta-llama/Llama-2-7b-hf")
# Create the sampling configs
generation_config = ff.GenerationConfig(
do_sample=True, temperature=0.9, topp=0.8, topk=1
)
# Compile the LLM for inference and load the weights into memory
llm.compile(generation_config)
# Generation begins!
result = llm.generate("Here are some travel tips for Tokyo:\n")
C++ interface
If you’d like to use the C++ interface (mostly used for development and benchmarking purposes), you should install from source, and follow the instructions below.
Expand here
Downloading models
Before running FlexFlow Serve, you should manually download the LLM and SSM(s) model of interest using the inference/utils/download_hf_model.py script (see example below). By default, the script will download all of a model's assets (weights, configs, tokenizer files, etc...) into the cache folder ~/.cache/flexflow. If you would like to use a different folder, you can request that via the parameter --cache-folder.
python3 ./inference/utils/download_hf_model.py <HF model 1> <HF model 2> ...
Running the C++ examples
A C++ example is available at this folder. After building FlexFlow Serve, the executable will be available at /build_dir/inference/spec_infer/spec_infer. You can use the following command-line arguments to run FlexFlow Serve:
- -ll:gpu: number of GPU processors to use on each node for serving an LLM (default: 0)
- -ll:fsize: size of device memory on each GPU in MB
- -ll:zsize: size of zero-copy memory (pinned DRAM with direct GPU access) in MB. FlexFlow Serve keeps a replica of the LLM parameters on zero-copy memory, and therefore requires that the zero-copy memory is sufficient for storing the LLM parameters.
- -llm-model: the LLM model ID from HuggingFace (e.g. "meta-llama/Llama-2-7b-hf")
- -ssm-model: the SSM model ID from HuggingFace (e.g. "JackFram/llama-160m"). You can use multiple -ssm-models in the command line to launch multiple SSMs.
- -cache-folder: the folder
- -data-parallelism-degree, -tensor-parallelism-degree and -pipeline-parallelism-degree: parallelization degrees in the data, tensor, and pipeline dimensions. Their product must equal the number of GPUs available on the machine. When any of the three parallelism degree arguments is omitted, a default value of 1 will be used.
- -prompt: (optional) path to the prompt file. FlexFlow Serve expects a json format file for prompts. In addition, users can also use the following API for registering requests:
- -output-file: (optional) filepath to use to save the output of the model, together with the generation latency
For example, you can use the following command line to serve a LLaMA-7B or LLaMA-13B model on 4 GPUs and use two collectively boost-tuned LLaMA-68M models for speculative inference.
./inference/spec_infer/spec_infer -ll:gpu 4 -ll:cpu 4 -ll:fsize 14000 -ll:zsize 30000 -llm-model meta-llama/Llama-2-7b-hf -ssm-model JackFram/llama-68m -prompt /path/to/prompt.json -tensor-parallelism-degree 4 --fusion
Speculative Inference
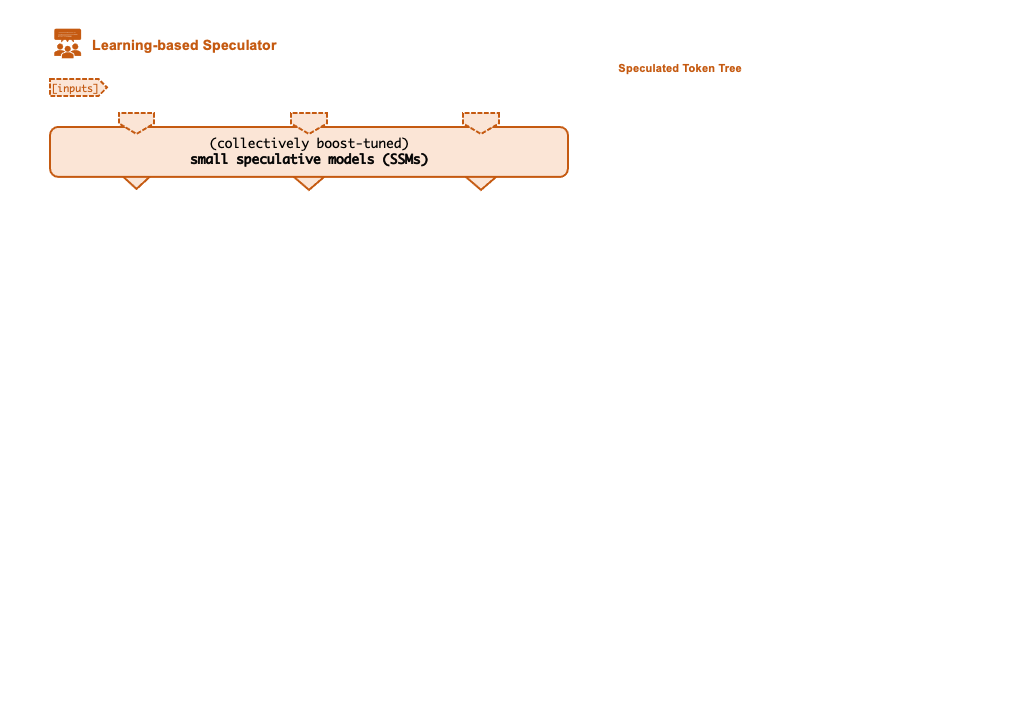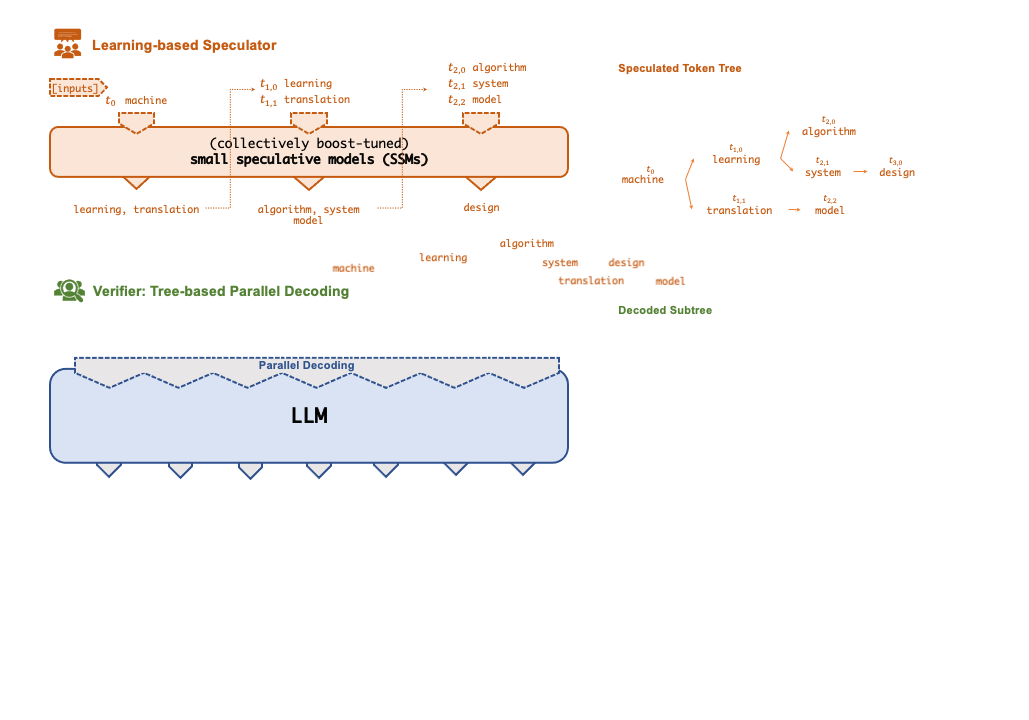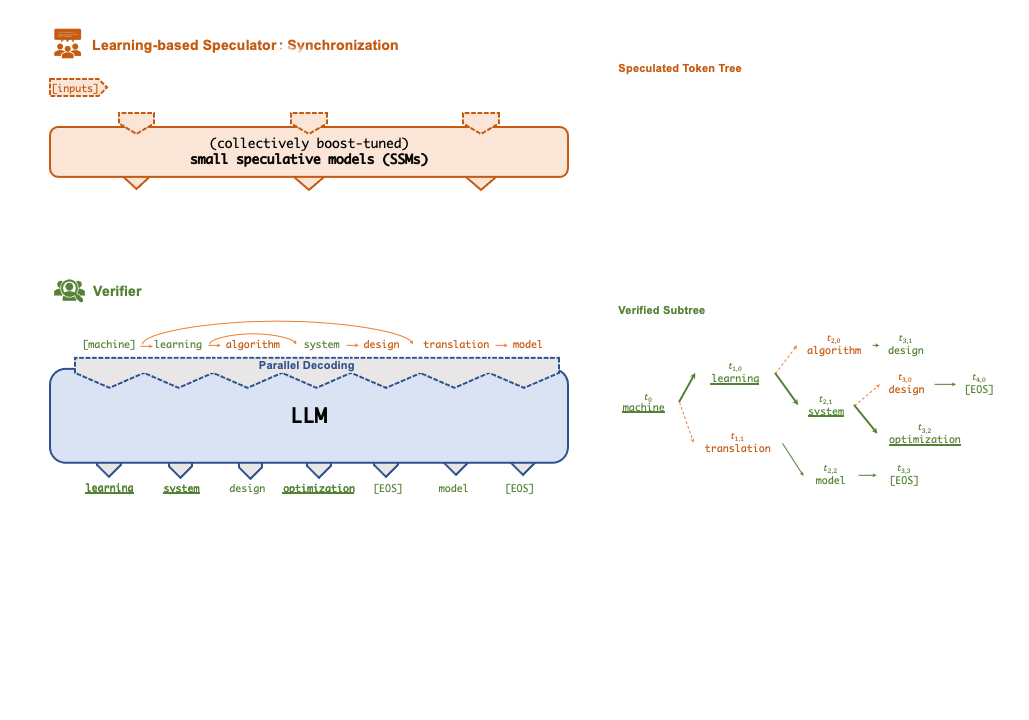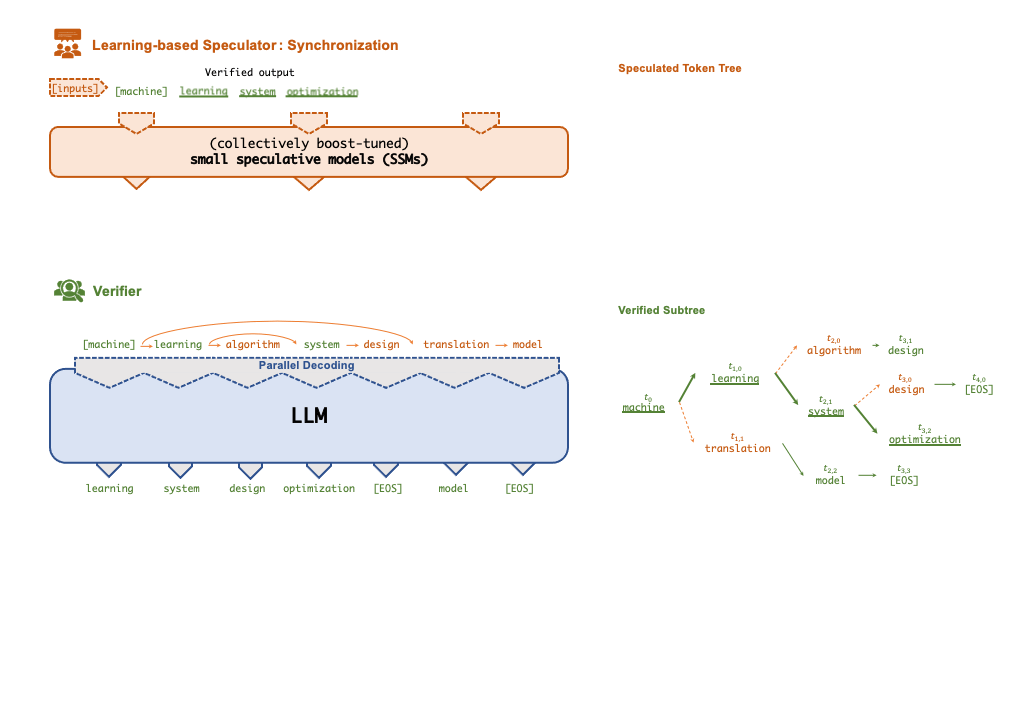
A key technique that enables FlexFlow Serve to accelerate LLM serving is speculative inference, which combines various collectively boost-tuned small speculative models (SSMs) to jointly predict the LLM’s outputs; the predictions are organized as a token tree, whose nodes each represent a candidate token sequence. The correctness of all candidate token sequences represented by a token tree is verified against the LLM’s output in parallel using a novel tree-based parallel decoding mechanism. FlexFlow Serve uses an LLM as a token tree verifier instead of an incremental decoder, which largely reduces the end-to-end inference latency and computational requirement for serving generative LLMs while provably preserving model quality.
Supported LLMs and SSMs
FlexFlow Serve currently supports all HuggingFace models with the following architectures:
LlamaForCausalLM/LLaMAForCausalLM(e.g. LLaMA/LLaMA-2, Guanaco, Vicuna, Alpaca, …)OPTForCausalLM(models from the OPT family)RWForCausalLM(models from the Falcon family)GPTBigCodeForCausalLM(models from the Starcoder family)
Below is a list of models that we have explicitly tested and for which a SSM may be available:
CPU Offloading
FlexFlow Serve also offers offloading-based inference for running large models (e.g., llama-7B) on a single GPU. CPU offloading is a choice to save tensors in CPU memory, and only copy the tensor to GPU when doing calculation. Notice that now we selectively offload the largest weight tensors (weights tensor in Linear, Attention). Besides, since the small model occupies considerably less space, it it does not pose a bottleneck for GPU memory, the offloading will bring more runtime space and computational cost, so we only do the offloading for the large model. [TODO: update instructions] You can run the offloading example by enabling the -offload and -offload-reserve-space-size flags.
Quantization
FlexFlow Serve supports int4 and int8 quantization. The compressed tensors are stored on the CPU side. Once copied to the GPU, these tensors undergo decompression and conversion back to their original precision. Please find the compressed weight files in our s3 bucket, or use this script from FlexGen project to do the compression manually. [TODO: update instructions for quantization].
Prompt Datasets
We provide five prompt datasets for evaluating FlexFlow Serve: Chatbot instruction prompts, ChatGPT Prompts, WebQA, Alpaca, and PIQA.
Python Interface Features and Interaction Methods
FlexFlow Serve provides a comprehensive Python interface for serving with low latency and high performance. This interface facilitates the deployment and interaction with the serving platform for a variety of applications, from chatbots and prompt templates to retrieval augmented generation and API services.
Chatbot with Gradio
The Python interface allows setting up a chatbot application using Gradio, enabling interactive dialogues with users through a user-friendly web interface.
Implementation Steps
FlexFlow Initialization: Configure and initialize FlexFlow Serve with the desired settings and the specific LLM. ```python import gradio as gr import flexflow.serve as ff
ff.init(num_gpus=2, memory_per_gpu=14000, …)
2. **Gradio Interface Setup:** Implement a function to generate responses from user inputs and set up the Gradio Chat Interface for interaction.
```python
def generate_response(user_input):
result = llm.generate(user_input)
return result.output_text.decode('utf-8')
Running the Interface: Launch the Gradio interface to interact with the LLM through a web-based chat interface. .. code-block:: python
iface = gr.ChatInterface(fn=generate_response) iface.launch()
Shutdown: Properly stop the FlexFlow server after interaction is complete.
Langchain Usecases
FlexFlow Serve supports langchain usecases including dynamic prompt template handling and RAG usecases, enabling the customization of model responses based on structured input templates and Retrieval Augmented Generation.
Implementation Steps
FlexFlow Initialization: Start by initializing FlexFlow Serve with the appropriate configurations.
LLM Setup: Compile and load the LLM for text generation.
Prompt Template/RAG Setup: Configure prompt templates to guide the model’s responses.
Response Generation: Use the LLM with the prompt template to generate responses.
Python FastAPI Entrypoint
Flexflow Serve also supports deploying and managing LLMs with FastAPI, offering a RESTful API interface for generating responses from models.
@app.on_event("startup")
async def startup_event():
global llm
# Initialize and compile the LLM model
llm.compile(
generation_config,
# ... other params as needed
)
llm.start_server()
@app.post("/generate/")
async def generate(prompt_request: PromptRequest):
# ... exception handling
full_output = llm.generate([prompt_request.prompt])[0].output_text.decode('utf-8')
# ... split prompt and response text for returning results
return {"prompt": prompt_request.prompt, "response": full_output}
TODOs
FlexFlow Serve is still under active development. We currently focus on the following tasks and strongly welcome all contributions from bug fixes to new features and extensions.
AMD benchmarking. We are actively working on benchmarking FlexFlow Serve on AMD GPUs and comparing it with the performance on NVIDIA GPUs.
Acknowledgements
This project is initiated by members from CMU, Stanford, and UCSD. We will be continuing developing and supporting FlexFlow Serve. Please cite FlexFlow Serve as:
@misc{miao2023specinfer,
title={SpecInfer: Accelerating Generative Large Language Model Serving with Speculative Inference and Token Tree Verification},
author={Xupeng Miao and Gabriele Oliaro and Zhihao Zhang and Xinhao Cheng and Zeyu Wang and Rae Ying Yee Wong and Alan Zhu and Lijie Yang and Xiaoxiang Shi and Chunan Shi and Zhuoming Chen and Daiyaan Arfeen and Reyna Abhyankar and Zhihao Jia},
year={2023},
eprint={2305.09781},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
License
FlexFlow uses Apache License 2.0.